本文描述了Scrapy的体系结构及其组件如何交互。 概述¶下图显示了Scrapy架构及其组件的概述,以及系统内部发生的数据流的概要(以红色箭头显示)。下面提供了这些组件的简要说明以及有关它们的详细信息的链接。数据流也描述如下。 数据流¶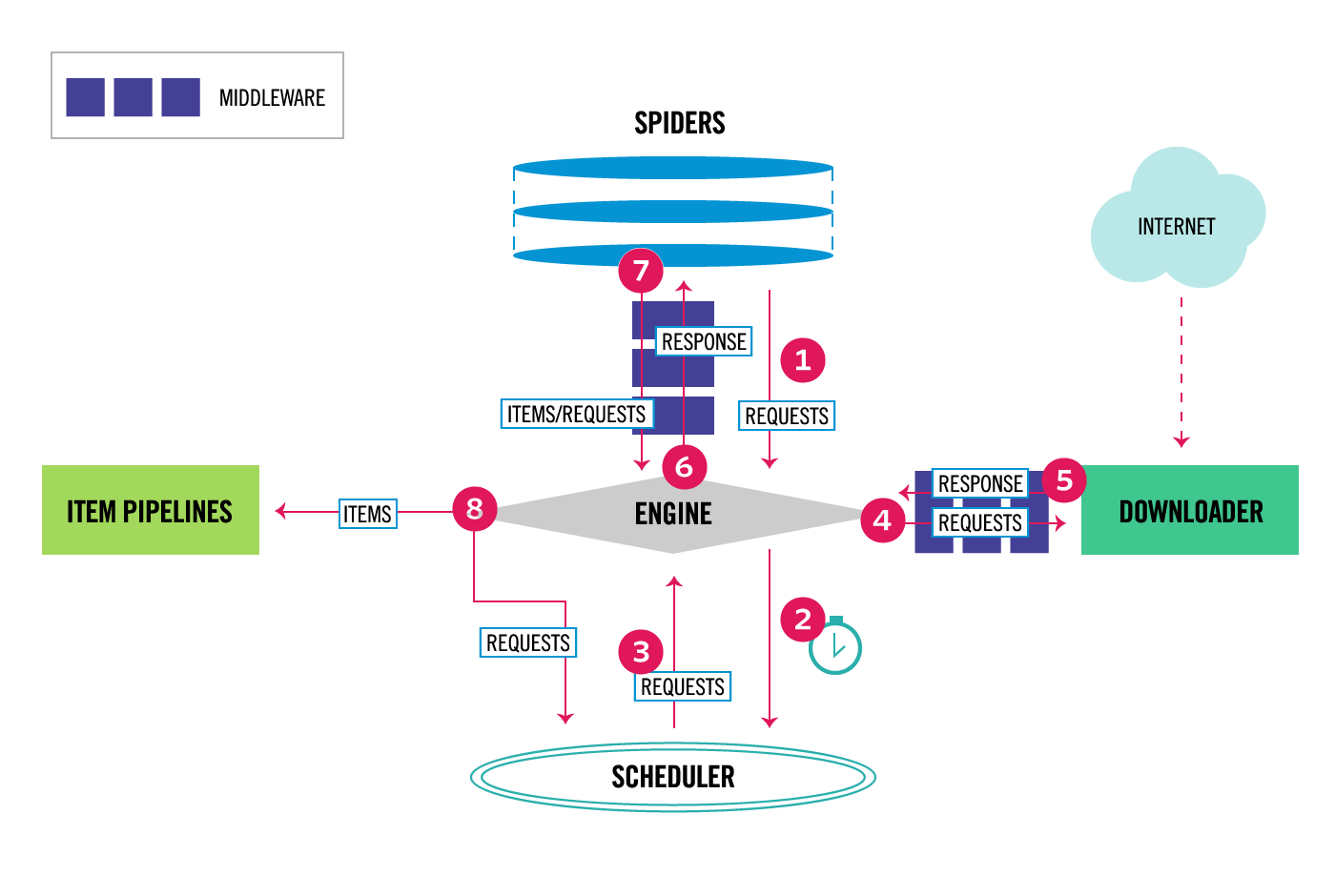 Scrapy中的数据流由执行引擎控制,如下所示:
组件¶抓取式发动机¶引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。见 Data Flow 有关详细信息,请参阅上面的部分。 调度程序¶这个 scheduler 接收来自引擎的请求,并将其排队,以便稍后在引擎请求它们时将其提供(也提供给引擎)。 下载器¶下载者负责获取网页并将其送入引擎,引擎反过来又将网页送入蜘蛛。 蜘蛛¶spider是Scrapy用户编写的自定义类,用于解析响应和提取 items 从他们或其他要求跟随。有关详细信息,请参阅 蜘蛛 . |
Archiver|手机版|笨鸟自学网 ( 粤ICP备20019910号 )
GMT+8, 2026-7-3 03:46 , Processed in 0.014882 second(s), 18 queries .