下面是关于如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了 Developer Tools 尽管我们将在本指南中使用firefox,但这些概念适用于任何其他浏览器。 在本指南中,我们将介绍通过抓取从浏览器的开发人员工具中使用的基本工具 quotes.toscrape.com 检查实时浏览器DOM时的注意事项¶由于开发人员工具在一个活动的浏览器DOM上运行,所以在检查页面源代码时,您实际上看到的不是原始的HTML,而是应用了一些浏览器清理和执行javascript代码后修改的HTML。尤其是火狐,以添加 因此,您应该记住以下几点:
查看网站¶到目前为止,开发人员工具最方便的特性是 Inspector feature, which allows you to inspect the underlying HTML code of any webpage. To demonstrate the Inspector, let's look at the quotes.toscrape.com 现场。 在这个网站上,我们总共有来自不同作者的十个引用,其中有特定的标签,还有前十个标签。假设我们想要提取这个页面上的所有引用,而不需要任何关于作者、标签等的元信息。 我们不必查看页面的整个源代码,只需右键单击一个报价并选择 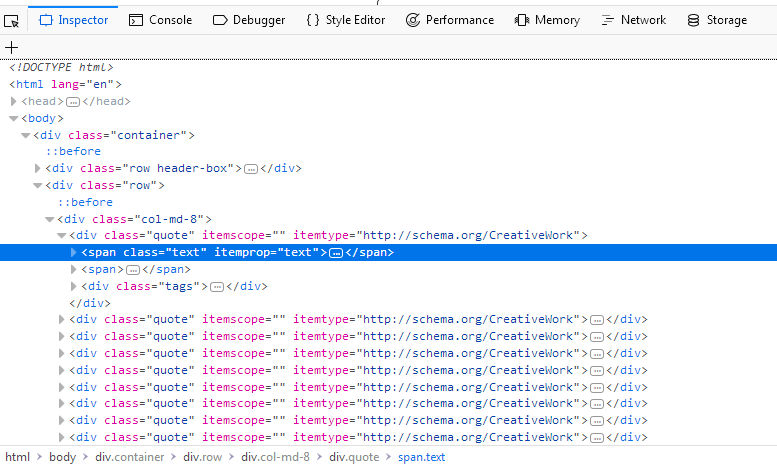 我们感兴趣的是: <div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
如果你在第一个上面徘徊 的优势 Inspector 它自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们扩大 |
Archiver|手机版|笨鸟自学网 ( 粤ICP备20019910号 )
GMT+8, 2026-8-3 17:12 , Processed in 0.020180 second(s), 18 queries .